Cos’è il file Robots.txt e perché è così importante per un sito?
- 19 Novembre 2024
- Guide SEO
Di la verità, hai mai pensato come i motori di ricerca esplorano il tuo sito? Immagina Google, Bing o qualsiasi altro crawler come degli esploratori instancabili che navigano tra le pagine web, mappandole per mostrarle nei risultati di ricerca all’utente. Ma cosa succede se ci sono parti del tuo sito che non vuoi far vedere? Magari pagine di login, aree in costruzione o contenuti duplicati che potrebbero confondere questi “esploratori” dei motori di ricerca? Ecco, qui entra in gioco il file robots.txt.
Questo piccolo file di testo, spesso ignorato e molto sottovalutato, è un vero guardiano digitale. Con poche righe di codice puoi dire ai motori di ricerca: “Ehi, questa parte del sito non è per voi” o, al contrario, “Questa è una zona da visitare, c’è la sitemap, entrate pure!”. È come mettere dei cartelli “accesso vietato” o “via libera” per i crawler.
Non farti ingannare dalla sua semplicità: il robots.txt è uno strumento potente che può fare la differenza nella gestione del tuo sito. Non si tratta solo di proteggere le aree riservate del sito; il suo utilizzo intelligente può ottimizzare il modo in cui il tuo sito viene esplorato, evitando sprechi di risorse e migliorando la tua visibilità. Ma attenzione, basta un errore in una singola riga e potresti finire per bloccare l’intero sito dai motori di ricerca. E ne ho visti parecchi di siti rovinati per una cattiva gestione del file robots.txt!
Cosa sono i file robots.txt
Il file robots.txt è, in parole semplici, una sorta di lettera di benvenutoper i motori di ricerca che visitano il tuo sito. Si tratta di un file di testo che si trova nella directory principale del sito web, accessibile all’indirizzo tuosito.it/robots.txt. Il suo compito? Dare istruzioni precise ai crawler su quali aree del tuo sito possono visitare e quali devono invece ignorare.
Se lo guardi da un punto di vista tecnico, il robots.txt è parte del Robots Exclusion Protocol, una sorta di regolamento internazionale per i motori di ricerca. Anche se non è obbligatorio che i crawler rispettino queste regole (alcuni potrebbero ignorarle, specialmente quelli “malintenzionati”), i principali motori di ricerca come Google, Bing e altri le seguono alla lettera.
Ma cosa c’è scritto in un file robots.txt? Di solito, include direttive semplici come:
- Allow: dà il permesso ai crawler di accedere a una specifica area.
- Disallow: impedisce l’accesso a determinate pagine o sezioni.
Ad esempio:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.phpQuesto esempio dice a tutti i crawler (indicati con User-agent: *) di non accedere all’area /wp-admin/, tranne al file admin-ajax.php, necessario per il funzionamento di alcune funzionalità del sito.
Anche se può sembrare un file semplice, il suo scopo è molto più strategico di quanto sembri. Puoi utilizzarlo per:
- Proteggere contenuti riservati: come pagine di amministrazione, documenti interni o aree in costruzione.
- Ottimizzare l’indicizzazione: dando priorità ai contenuti più importanti ed evitando che i motori di ricerca si perdano in pagine inutili o duplicati.
- Risparmiare risorse: evitando che i crawler sprechino il tuo crawl budget (il tempo e le risorse che un motore di ricerca dedica al tuo sito).
Il file robots.txt non è pensato per nascondere informazioni sensibili (per quello ci sono altri metodi, come l’autenticazione), ma per guidare i motori di ricerca nella navigazione del tuo sito. Un errore comune? Pensare che aggiungere un “Disallow” impedisca completamente l’accesso a quelle pagine. I contenuti bloccati non vengono esplorati, ma potrebbero comunque comparire nei risultati di ricerca se vengono linkati da altre pagine.
A cosa serve il file robots.txt
Il file robots.txt è molto più di un semplice elenco di regole per i motori di ricerca. È uno strumento fondamentale per prendere il controllo su come i crawler interagiscono con il tuo sito, influenzando non solo la SEO, ma anche la gestione complessiva delle risorse del sito stesso.
Bloccare contenuti non rilevanti
Uno degli usi principali del file robots.txt è impedire l’accesso a sezioni del sito che non hanno valore per gli utenti finali o che potrebbero generare confusione nei motori di ricerca. Ad esempio, potresti voler bloccare:
- Pagine amministrative come
/wp-admin/o/login/. - File temporanei o cartelle in sviluppo.
- Contenuti duplicati che potrebbero danneggiare la tua SEO (come versioni stampabili delle pagine o archivi datati).
Bloccare questi contenuti evita che vengano analizzati e indicizzati, proteggendo così la qualità complessiva del tuo sito nei risultati di ricerca.
Ottimizzare il crawl budget
Il crawl budget è la quantità di tempo e risorse che un motore di ricerca dedica all’esplorazione del tuo sito. Per i siti più piccoli potrebbe non essere un problema, ma per portali di grandi dimensioni o e-commerce con migliaia di pagine, il crawl budget diventa cruciale. Attraverso il file robots.txt, puoi dire ai motori di ricerca di concentrarsi solo sulle pagine più importanti, ignorando quelle meno rilevanti.
Per esempio, se gestisci un negozio online, potresti voler bloccare le pagine di ricerca interna o filtri di prodotto, che generano URL infiniti e inutili per il posizionamento.
Evitare l’indicizzazione di contenuti sensibili
Sebbene il robots.txt non garantisca una protezione totale (i contenuti bloccati possono essere comunque accessibili se linkati pubblicamente), è utile per evitare che alcune pagine appaiano nei risultati di ricerca. Un classico esempio? La pagina dei termini e condizioni, che non interessa a nessuno tranne che agli utenti specifici che ne hanno bisogno.
Guidare il comportamento dei crawler
Ogni motore di ricerca ha il suo crawler (Google usa Googlebot, Bing ha Bingbot, ecc.) e con il robots.txt puoi indirizzarli in modo specifico. Vuoi che solo Google esplori una determinata sezione? Basta indicare nel file:
User-agent: Googlebot
Allow: /sezione-specifica/Questo livello di controllo è particolarmente utile per strategie SEO avanzate o per testare nuove sezioni del sito senza esporle immediatamente a tutti i motori di ricerca.
Collaborare con la Sitemap XML
Il file robots.txt è anche un mezzo per comunicare ai motori di ricerca la posizione della tua Sitemap XML, il documento che elenca tutte le pagine che vuoi indicizzare. Basta aggiungere una riga come questa:
Sitemap: https://www.tuosito.it/sitemap.xmlQuesto aiuta i motori di ricerca a trovare e indicizzare rapidamente i contenuti più importanti.
Evitare sprechi di risorse
Ogni volta che un crawler visita il tuo sito, utilizza risorse: sia lato server, sia lato crawler. Impostare correttamente il file robots.txt permette di risparmiare queste risorse, evitando che i bot esplorino pagine inutili o generino un carico eccessivo sul server.
Importanza del robots.txt nella SEO
Il file robots.txt non è solo una questione tecnica, ma una vera e propria strategia per ottimizzare la visibilità e il posizionamento nei motori di ricerca.
Gestire l’indicizzazione con precisione chirurgica
Un sito ben indicizzato è un sito che offre ai motori di ricerca esattamente ciò che vogliono: contenuti rilevanti e di valore. Puoi:
- Evitare che vengano indicizzate pagine inutili o non strategiche.
- Prevenire la comparsa di contenuti duplicati, che possono penalizzare il posizionamento del sito.
- Mantenere un focus chiaro sulle pagine che vuoi rendere visibili, migliorando la tua presenza nei risultati di ricerca.
Immagina di gestire un e-commerce con migliaia di prodotti. Non vuoi che i motori di ricerca perdano tempo su pagine di ricerca interna o URL generati da filtri, che spesso non portano traffico di qualità. Grazie al robots.txt, puoi bloccare queste sezioni e concentrare il crawl budget sui prodotti e le categorie principali.
Crawl budget: la chiave dell’efficienza
Il crawl budget è una risorsa limitata, specialmente per siti molto grandi. Ogni motore di ricerca decide quanto tempo dedicare al tuo sito in base alla sua rilevanza e struttura. Se i crawler passano troppo tempo su pagine inutili o ripetitive, rischi che contenuti importanti vengano ignorati.
Con un robots.txt ben configurato, puoi:
- Massimizzare l’efficienza del crawl budget.
- Garantire che i motori di ricerca dedichino più tempo alle pagine strategiche.
- Evitare che il tuo sito sembri disorganizzato o difficile da navigare.
Come creare un file robots.txt efficace
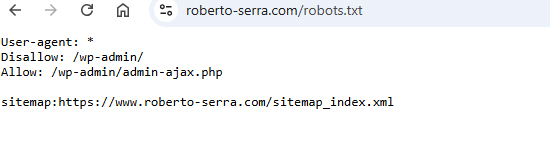
Creare un file robots.txt non è una missione impossibile. Basta un editor di testo, qualche regola chiara e un po’ di attenzione. Qui sopra hai come esempio il file di uno dei SEO più famosi ed importanti d’italia, Roberto Serra, di cui nutro il massimo rispetto. Un file pulito, senza troppi fronzoli che indica cosa seguire e cosa no.
Strumenti per creare il file robots.txt
Non hai bisogno di software complicati per iniziare. Puoi utilizzare un semplice editor di testo come Notepad (Windows), TextEdit (Mac) o strumenti più avanzati come Visual Studio Code. Assicurati che il file venga salvato come robots.txt in formato testo semplice, senza alcuna formattazione.
Se preferisci qualcosa di più guidato, molti CMS come WordPress offrono plugin (ad esempio, Yoast SEO o Rank Math) che generano automaticamente un file robots.txt personalizzabile.
Posizione del file
Il file robots.txt deve essere posizionato nella root directory del tuo sito, ovvero il livello più alto della struttura. Se non è nella root, i crawler non saranno in grado di trovarlo. Il tuo file dovrebbe essere accessibile tramite:
https://www.tuosito.it/robots.txtSe non riesci a posizionarlo correttamente, potrebbe essere necessario l’accesso FTP o il pannello di controllo del tuo hosting.
Struttura del file robots.txt
Il file segue una struttura semplice, basata su direttive come User-agent, Disallow e Allow. Ecco un esempio base:
User-agent: *
Disallow: /cartella-bloccata/
Allow: /cartella-bloccata/file-consentito.html
Sitemap: https://www.tuosito.it/sitemap.xml- User-agent: specifica a quale crawler si applicano le regole. L’asterisco (*) indica che le regole valgono per tutti i crawler.
- Disallow: blocca l’accesso a una determinata pagina o cartella.
- Allow: consente l’accesso a specifici contenuti, anche in cartelle bloccate.
- Sitemap: indica la posizione della tua Sitemap XML per facilitare l’indicizzazione.
Best practice per un file robots.txt efficace
- Mantieni il file semplice: evita di complicarlo con regole superflue. Un file troppo complesso può confondere sia te che i crawler.
- Non bloccare file essenziali: assicurati che risorse come CSS e JavaScript non siano bloccate. Questi file sono fondamentali per il rendering delle tue pagine.
- Usa i wildcard con cautela: simboli come
*(qualsiasi carattere) o$(fine URL) possono essere utili, ma un errore di configurazione potrebbe bloccare più del previsto. - Blocca solo ciò che serve: non è necessario bloccare tutto. Concentrati su aree che non vuoi che i crawler esplorino o indicizzino.
- Indica la Sitemap: aggiungere il percorso della tua Sitemap nel file robots.txt aiuta i crawler a scoprire e indicizzare più facilmente le pagine importanti.
Esempio di configurazioni
- Sito base o blog:
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://www.tuosito.it/sitemap.xml- E-commerce:
User-agent: *
Disallow: /checkout/
Disallow: /cart/
Disallow: /search/
Sitemap: https://www.tuosito.it/sitemap.xml- Blocco temporaneo per sviluppo:
User-agent: *
Disallow: /(Nota: usa questa configurazione con attenzione e solo per siti in fase di test.)
Test del file robots.txt
Prima di implementare il file, testalo per verificare che funzioni come previsto. Puoi utilizzare strumenti come:
- Google Search Console: offre un tester specifico per il robots.txt.
- Screaming Frog: permette di simulare il comportamento dei crawler sul tuo sito.
- Visualizzazioni manuali: prova ad accedere alle pagine bloccate direttamente per vedere se vengono rispettate le regole.
Aggiornamento e manutenzione
Non dimenticare di aggiornare il file robots.txt ogni volta che apporti modifiche importanti alla struttura del tuo sito. Una buona manutenzione ti aiuterà a evitare problemi di indicizzazione e a garantire che i crawler si comportino come previsto
Errori comuni da evitare con il file robots.txt
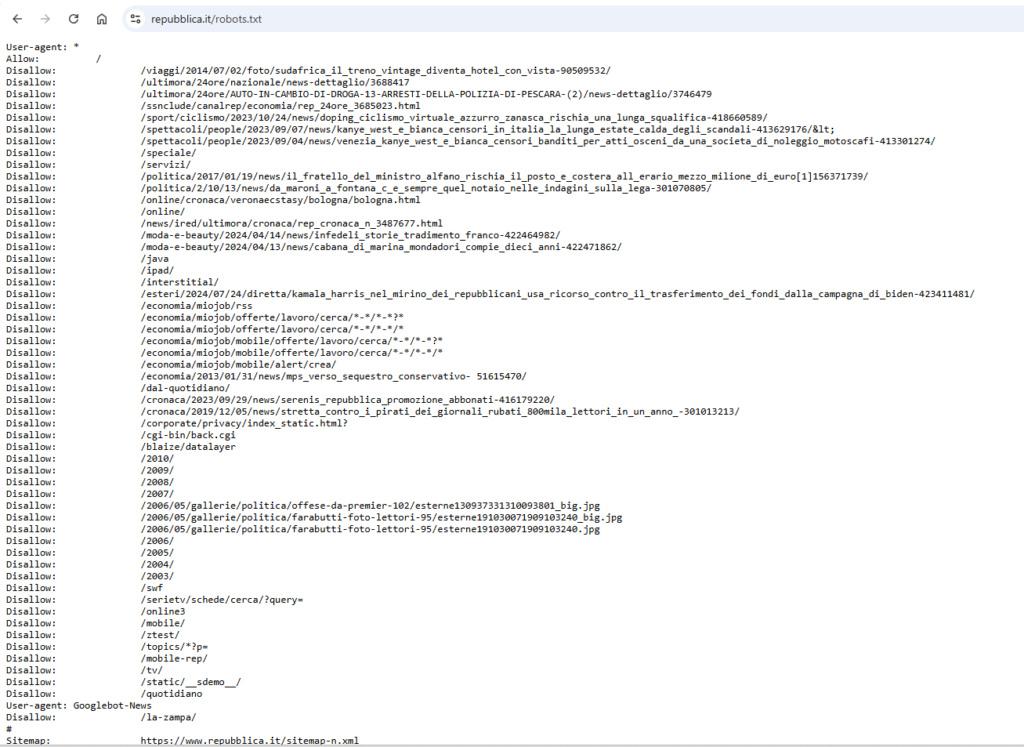
Questo che vedi qui sopra è un esempio del file robots.txt del sito repubblica e possiamo constatare di quanto può essere complicato e difficile seguirlo, basta un singolo errore e il danno è bello grande.
Molto curioso è il fatto di aver messo in disallow molte pagine interne di articoli.
Per questo ti dico che se il file robots.txt sembra semplice da configurare, è altrettanto facile incappare in errori che possono compromettere seriamente la visibilità del tuo sito sui motori di ricerca. Qui entriamo nel vivo di ciò che non devi fare e come evitare problemi potenzialmente catastrofici.
Bloccare l’intero sito accidentalmente
L’errore più grave e sorprendentemente comune è quello di bloccare l’accesso a tutto il sito. Una direttiva come questa può trasformare il tuo sito in una terra proibita per i motori di ricerca:
User-agent: *
Disallow: /Questa configurazione è utile solo in fase di sviluppo o manutenzione, ma se lasciata attiva su un sito live, rischi di perdere tutto il traffico organico. Prima di pubblicare il tuo file robots.txt, verifica attentamente ogni riga.
Bloccare risorse essenziali
Un altro errore comune è bloccare file fondamentali come CSS e JavaScript. Questi file sono cruciali per il rendering delle pagine, e se i crawler non possono accedervi, potrebbero interpretare male il contenuto o la struttura del sito. Ad esempio, un blocco sbagliato come questo può causare problemi:
User-agent: *
Disallow: /wp-content/In questo caso, potresti impedire l’accesso a file che servono a caricare immagini, stili e script.
Dimenticare di aggiornare il file
Il tuo sito non è statico, quindi il file robots.txt non dovrebbe esserlo. Modifiche strutturali, nuove sezioni o pagine obsolete richiedono un aggiornamento delle regole. Un file datato può portare a:
- Blocchi di contenuti che vorresti indicizzare.
- Mancata protezione di nuove sezioni sensibili.
Pianifica controlli regolari del tuo file robots.txt, specialmente dopo importanti aggiornamenti del sito.
Confondere il robots.txt con il noindex
Molti pensano che aggiungere una direttiva Disallow al robots.txt impedisca ai motori di ricerca di indicizzare una pagina. Non è così. Se una pagina bloccata è linkata altrove, potrebbe comunque comparire nei risultati di ricerca, anche se i motori di ricerca non possono esplorarne il contenuto. Per evitare questa situazione, usa i meta tag noindex direttamente nella pagina.
Ad esempio:
- Disallow nel robots.txt: blocca l’accesso ai crawler.
- Noindex nella pagina: impedisce l’indicizzazione nei risultati di ricerca.
Per ottenere il massimo controllo, spesso è necessario combinare entrambe le strategie.
Non testare il file
Pubblicare un file robots.txt senza verificarlo è come lanciare un prodotto senza fare test. Gli errori possono essere devastanti e passare inosservati per settimane, se non mesi. Utilizza strumenti come il Tester del robots.txt di Google Search Console per simulare il comportamento dei crawler e verificare che le regole funzionino come previsto.
Non considerare i crawler malintenzionati
Non tutti i crawler rispettano le regole del tuo robots.txt. Alcuni bot “malintenzionati” potrebbero ignorarlo completamente. Sebbene il file robots.txt sia utile per i motori di ricerca legittimi, non può proteggere completamente il tuo sito da accessi indesiderati. Per una maggiore sicurezza, considera di combinare il robots.txt con altre misure, come blocchi a livello di server (es. file .htaccess).
Eccesso di blocchi
Bloccare troppe pagine o sezioni può limitare inutilmente l’indicizzazione del tuo sito. Ricorda: il file robots.txt dovrebbe servire a guidare i motori di ricerca, non a ostacolarli. Chiediti sempre:
- Questa pagina o cartella è davvero inutile per la SEO?
- È più importante bloccarla o ottimizzarla?
Un approccio bilanciato ti aiuterà a ottenere il massimo beneficio senza sacrificare opportunità.
Come verificare e testare il file robots.txt
Una volta creato o aggiornato il file robots.txt, il lavoro non è finito. Testare e verificare che funzioni correttamente è un passaggio cruciale per evitare errori che potrebbero compromettere l’indicizzazione del sito. Fortunatamente, ci sono strumenti e tecniche che ti permettono di assicurarti che il file sia configurato correttamente e stia facendo esattamente quello che vuoi.
Verifica manuale
Il primo passo è semplice: accedi al tuo file robots.txt direttamente dal browser. Inserisci l’indirizzo:
https://www.tuosito.it/robots.txtSe il file è visibile, sei sulla strada giusta. Leggilo attentamente e controlla che le regole siano chiare e corrette. Se il file non viene trovato, verifica che sia posizionato nella root directory del sito.
Strumenti di testing online
Esistono strumenti online che ti permettono di simulare il comportamento dei crawler rispetto al tuo file robots.txt. Ecco i principali:
- Google Search Console – Tester robots.txt
Google Search Console offre un tool specifico per testare il file robots.txt. Ecco come usarlo:
- Accedi a Google Search Console e seleziona il tuo sito.
- Vai alla sezione “Strumenti e rapporti” e cerca il tester robots.txt.
- Inserisci un URL del tuo sito e verifica se il file consente o blocca correttamente l’accesso al crawler di Google. Questo strumento è particolarmente utile perché evidenzia eventuali errori o righe mal configurate.
- Screaming Frog
Screaming Frog è un crawler avanzato che ti consente di analizzare il tuo sito come farebbe un motore di ricerca. Puoi configurarlo per rispettare le regole del tuo robots.txt e verificare se blocca correttamente le sezioni che desideri. - Ahrefs o SEMrush
Questi strumenti SEO non solo analizzano il tuo file robots.txt, ma ti danno una panoramica completa di come il tuo sito viene visto dai motori di ricerca. Puoi vedere se ci sono pagine bloccate che dovrebbero essere indicizzate o errori che influenzano il crawl budget.
Simulazione dei crawler
Un metodo efficace per verificare il comportamento del file robots.txt è simulare i principali crawler dei motori di ricerca. Ad esempio:
- Testa come Googlebot accede al tuo sito con il tester di Google.
- Usa strumenti come Sitebulb per simulare crawler multipli (Google, Bing, Yahoo, ecc.).
Analisi dei log del server
I log del server sono una risorsa preziosa per capire come i crawler interagiscono con il tuo sito. Analizzando questi file puoi verificare:
- Quali URL vengono esplorati dai crawler.
- Se i crawler stanno rispettando le regole del tuo robots.txt.
- Se ci sono tentativi di accesso non desiderati.
Questo metodo richiede un po’ più di conoscenza tecnica, ma offre un quadro completo del comportamento dei bot sul tuo sito.
Errori comuni rilevati durante i test
Durante i test, potresti imbatterti in alcuni problemi comuni:
- Regole ambigue: Se due regole si contraddicono, i crawler potrebbero non seguire nessuna delle due. Assicurati che ogni direttiva sia chiara e non sovrapposta.
- Blocchi inaspettati: Pagine che dovrebbero essere accessibili risultano bloccate. In questi casi, controlla attentamente l’uso di wildcard o percorsi errati.
- Mancanza di aggiornamenti: Il file robots.txt potrebbe essere correttamente configurato, ma non aggiornato con le ultime modifiche strutturali del sito.
Buone pratiche per il testing
- Effettua test regolari, soprattutto dopo aver apportato modifiche significative al sito.
- Coinvolgi strumenti di terze parti per avere una visione esterna del tuo file robots.txt.
- Controlla sempre il comportamento su più crawler, non solo su Googlebot.
Testare e verificare il tuo file robots.txt è un passaggio essenziale per mantenere il controllo sul comportamento dei crawler. Grazie agli strumenti disponibili e a un approccio sistematico, puoi evitare errori che potrebbero penalizzare la tua SEO e assicurarti che il tuo sito sia esplorato esattamente come desideri.







